NoSQL
Motivation and History
Online Transaction Processing (OLTP) is a class of workloads characterized by high numbers of transactions executed by large numbers of users.
Online Analytical Processing is a class of read-only workloads characterized by queries that typically touch a large amount of data.
In many cases, OLTP and OLAP workloads are served by separate databases. Data must be migrated from OLTP systems to OLAP systems every so often via a process called extract-transform-load (ETL).
NoSQL: Scaling Databases for Web 2.0
Relaxing the guarantees and reducing the functionality provided by relational databases. The resulting databases, termed NoSQL, exhibit a simpler data model with restricted updates but can handle a higher volume of simple updates and queries.
One-tier Architecture
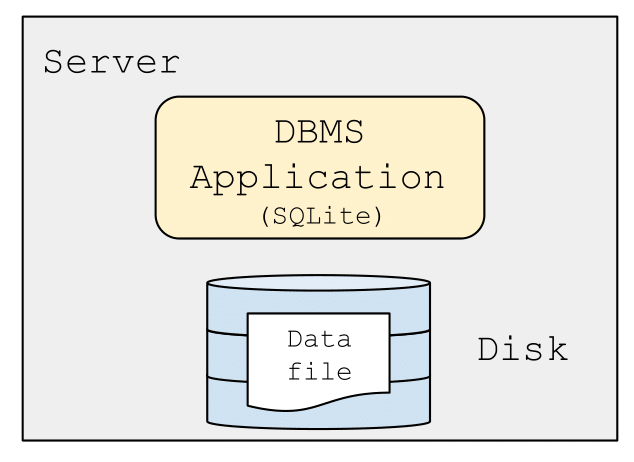
Two-tier Architecture

Three-tier Architecture

Application servers can be replicated in order to meet this scale. Application servers are relatively easy to replicate because they do not share state (i.e., the only state they need to keep is which clients are connected to them)
Methods for Scaling Databases
Partitioning
Queries can be executed in parallel on multiple machines if they touch different parts of the database and 2) partitioning the database may allow each partition to fit into memory, which can reduce the disk I/O cost for executing queries. Partitioning can be effective for write-heavy workloads, as query write operations such as inserts and updates, will likely involve writing to just a single machine.
Replication
This is effective for read-heavy workloads, as queries that read the same data can be executed in parallel on different replicas. However, as the number of replicas increases, writes become increasingly expensive, as queries that update data must now write to each replica of the data to keep them in sync.
Partitioning and replication are often used together in real systems to leverage the performance benefits and to make the system more fault-tolerant.
CAP Theorem
In reality, it is almost impossible to design a system that is completely safe from network failures, and thus most systems must be designed with partition tolerance in mind. So usually it's a tradeoff between consistency and availability.
A system that chooses consistency over availability will return an error or time-out if it cannot ensure that the data view it has access to contains the most recent updates. On the other hand, a system that chooses availability over consistency will always respond with the data view it has access to, even if it is unable to ensure that it contains the most recent updates.
Example: A client reading from a replica that cannot access the main copy/replica (due to a network failure). The client will either receive an error (prioritizing consistency) or a stale copy (prioritizing availability).
In fact many such systems provide eventual consistency instead of consistency, in order to trade off availability and consistency.
Eventual consistency allows for better performance, as write operations no longer have to ensure that the update has been successful on all replicas. Instead, the update can be propagated to the rest of the replicas asynchronously.
Relational databases chooses consistency and NoSQL chooses availability.
NoSQL Data Models
NoSQL data stores encompass a number of different data models that differ from the relational model.
NoSQL is not ACID compliant. It conforms to Base (Basically Available, Soft State, Eventual Consistency)
Basically available: guarantee availability
Soft state: the state of the system could change over time, even during times without input there may be changes going on due to 'eventual consistency'.
Eventual consistency

Key-Value Stores
It is typical for a KVS to only allow for byte-array values, which means the application has the responsibility of serializing/deserializing various data types into a byte-array. Due to the flexibility of the KVS data model, a KVS cannot perform operations on the values, and instead provides just three operations: get(key), put(key, value) and update(key, value).
Column-Family Stores
Columns rather than rows are stored together on disk. Related columns grouped together into families.
Document Stores
Key-value stores whose values adhere to a semi-structured data format such as JSON, XML or Protocol Buffers are termed document stores; the values are called documents. Relational databases store tuples in tables; document databases store documents in collections.
Graph Databases
A graph is a node-and-arc network.
Social graphs are common examples. Graphs are difficult to program in relational DB. A graph DB stores entities and their relationships.
Aggregate-oriented databases: These types of databases are designed to store, retrieve, and manage groupings of data, known as "aggregates". An aggregate is a collection of objects that are considered as one unit with respect to data manipulation.
Key-value, document store and column-family are "aggregate-oriented-store business object" in its entirely databases.
Document vs Relational Data Models
JSON supports the following types:
Object: collection of key-value pairs. Keys must be strings. Values can be any JSON type (i.e., atomic, object, or array). Objects should not contain duplicate keys. Objects are denoted using “{“ and “}” in a JSON document.
Array: an ordered list of values. Values can be any JSON type (i.e. atomic, object, or array). Arrays are denoted using “[” and “]” in a JSON document.
Atomic: one of a number (a 64-bit float), string, boolean or
null.
Relational databases are sometimes described as “enforcing schema on write”, and document databases are sometimes described as “enforcing schema on read”. Applications querying a relational database will know exactly the structure and data types of the rows that are returned; this can be determined through examining the schemas of the tables being queried. However, applications querying a document database will need to inspect the schema of each document in a collection, which pushes complexity into the application logic.

The document model is more suitable for data which is primarily accessed by a primary key (like an email or user ID). For these kinds of lookups, the document model exhibits better locality; all the data related to the key of interest can be returned in a single query.
Converting
Three options to convert relational database to JSON:
Let's make this concept more tangible by considering a real-world example. Suppose we have three tables in a relational database schema: Authors, Books, and AuthorBook which captures the many-to-many relationship between authors and books (since a book can have multiple authors and an author can write multiple books). Here's how the tables might look:
Authors:
Books:
AuthorBook:
Now, let's consider the three JSON representation options:
Flat JSON arrays for each table: This approach would represent each table as a separate JSON array, each element of which is an object representing a row.
There's no redundant data here, but the application has to "join" the tables to get related data, i.e., to find out which author wrote which book.
Keying off the Authors table: The second option might key off of the Authors table and inline the contents of the AuthorBook and Books tables within each Author object.
Here, information about "Book2" is duplicated for each linked Author. This redundancy means the application doesn't need to perform any joins, but updates will have to handle updating all duplicated rows.
Keying off the Books table: The third option might key off of the Books table and inline the contents of the AuthorBook and Authors tables within each Book object.
In this case, information about "AuthorA" is duplicated for each linked Book. The same trade-off applies: no need for joins, but updates must handle duplicated rows.
Converting JSON to relational database is rather tricky.
Last updated